Android 屏幕刷新
前言:
现在 Android 的应用界面越来越复杂,很多时候页面中还有各种动画,所以页面卡顿、掉帧等问题就随之而来,因此了解 Android 的屏幕刷新原理就显得尤为重要,只有抓住最根本的原理,才能快速定位和解决问题。

基本概念
CPU
执行应用层的 measure、layout、draw 等操作,绘制完成后将数据提交给 GPU。
GPU
进一步处理数据,并将数据缓存起来。
软件绘制与硬件绘制
UI 组件在绘制到屏幕之前,都需要经过 Rasterization(栅格化)操作,而栅格化操作又是一个非常耗时的操作。 GPU(Graphic Processing Unit )也就是图形处理器,它主要用于处理图形运算,可以帮助我们加快栅格化操作。
Android图形组件
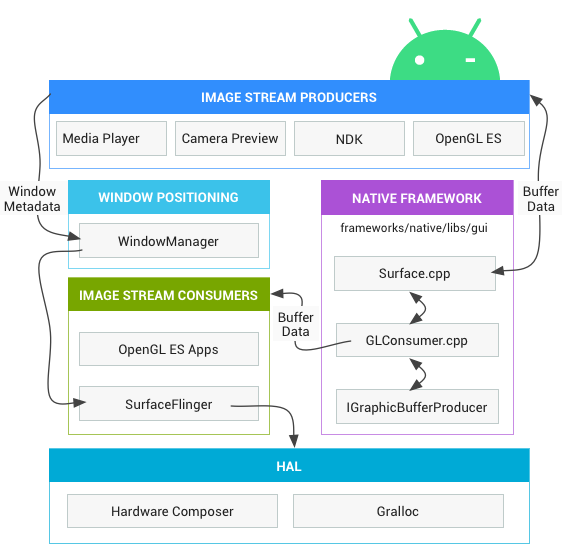
如果把应用程序图像渲染过程当作一次绘画过程,那么绘画过程中 Android 的各个图形组件的作用是:
画笔:Skia 或者 OpenGL。我们可以用 Skia 画笔绘制 2D 图形,也可以用 OpenGL 来 绘制 2D/3D 图形。正如前面所说,前者使用 CPU 绘制,后者使用 GPU 绘制。
画纸:Surface。所有的元素都在 Surface 这张画纸上进行绘制和渲染。在 Android 中,Window 是 View 的容器,每个窗口都会关联一个 Surface。而 WindowManager 则负责管理这些窗口,并且把它们的数据传递给 SurfaceFlinger。
画板:Graphic Buffer。Graphic Buffer 缓冲用于应用程序图形的绘制,在 Android 4.1 之前使用的是双缓冲机制;在 Android 4.1 之后,使用的是三缓冲机制。
显示:SurfaceFlinger。它将 WindowManager 提供的所有 Surface,通过硬件合成器 Hardware Composer 合成并输出到显示屏。
硬件加速
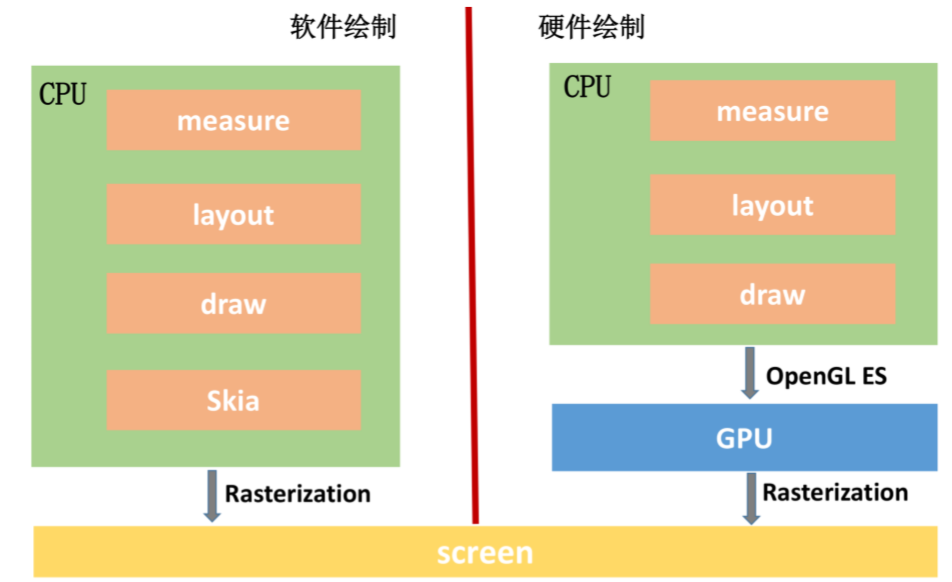
1. 软件绘制
在 Android 3.0 之前,或者没有启用硬件加速时,系统都会使用软件方式来渲染 UI。
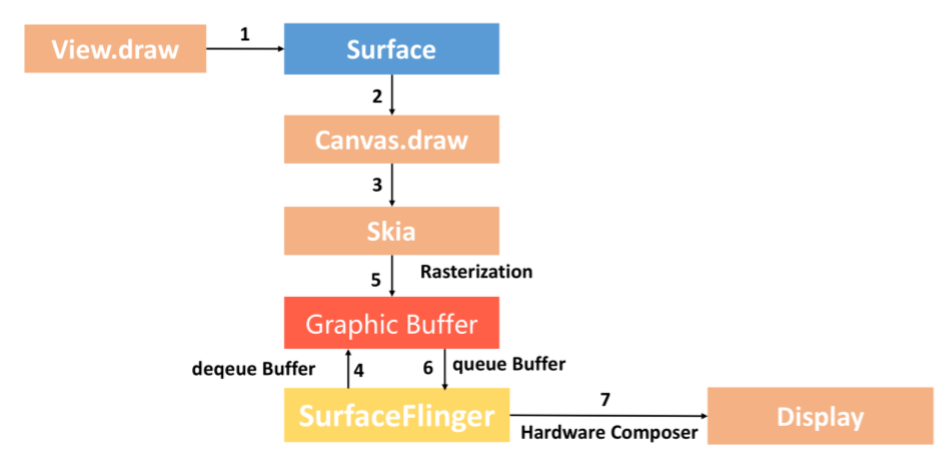
整个流程如上图所示:
Surface。每个 View 都由某一个窗口管理,而每一个窗口都关联有一个 Surface。
Canvas。通过 Surface 的 lock 函数获得一个 Canvas,Canvas 可以简单理解为 Skia 底层接口的封装。
Graphic Buffer。SurfaceFlinger 会帮我们托管一个 BufferQueue,我们从 BufferQueue 中拿到 Graphic Buffer,然后通过 Canvas 以及 Skia 将绘制内容栅格化 到上面。
SurfaceFlinger。通过 Swap Buffer 把 Front Graphic Buffer 的内容交给 SurfaceFinger,最后硬件合成器 Hardware Composer 合成并输出到显示屏。
2. 硬件加速绘制
从 Androd 3.0 开始,Android 开始支持硬件加速,到 Android 4.0 时,默认开启硬件加速。
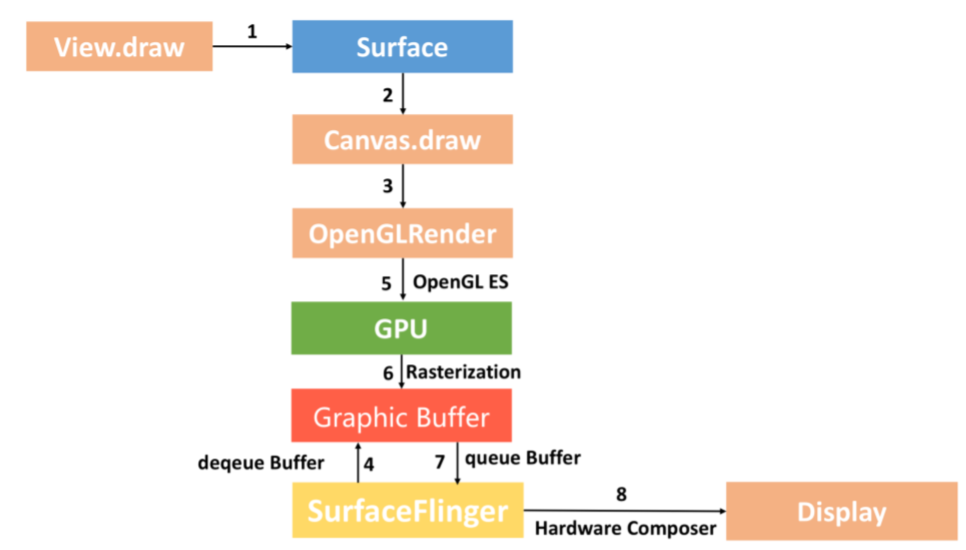
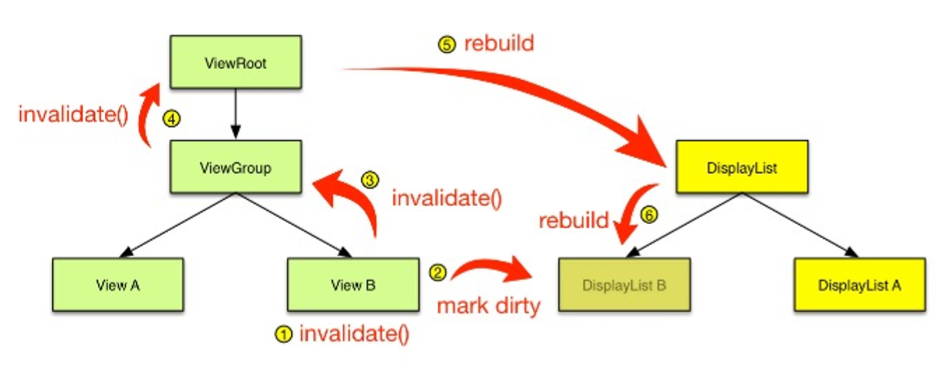
硬件加速绘制与软件绘制整个流程差异非常大,最核心就是我们通过 GPU 完成 Graphic Buffer 的内容绘制。此外硬件绘制还引入了一个 DisplayList 的概念,每个 View 内部都有一个 DisplayList,当某个 View 需要重绘时,将它标记为 Dirty。
当需要重绘时,仅仅只需要重绘一个 View 的 DisplayList,而不是像软件绘制那样需要向上递归。这样可以大大减少绘图的操作数量,因而提高了渲染效率。
什么是屏幕刷新率?
首先我们需要知道什么是屏幕刷新率,简单来说,屏幕刷新率是一个硬件的概念,是说屏幕这个硬件刷新画面的频率。
举例来说,60Hz 刷新率意思是:这个屏幕在 1 秒内,会刷新显示内容 60 次;那么对应的,90Hz 是说在 1 秒内刷新显示内容 90 次。至于显示的内容是什么,屏幕这边是不关心的,他只是从规定的地方取需要显示的内容,然后显示到屏幕上。
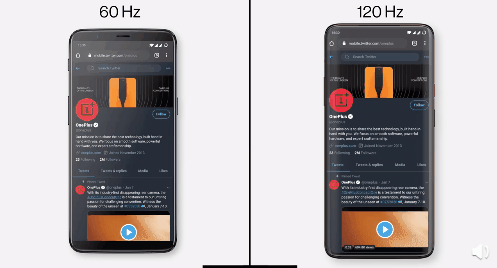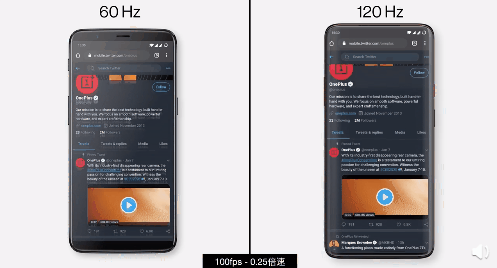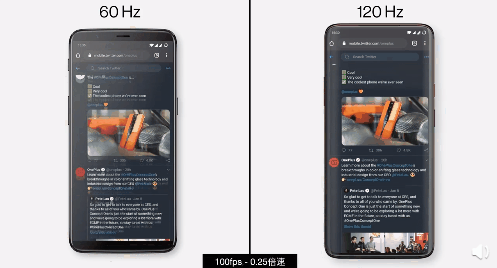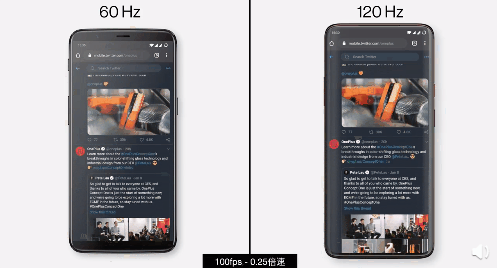
什么是FPS?
首先需要说明的是 FPS 是一个软件的概念,与屏幕刷新率这个硬件概念要区分开,FPS 是由软件系统决定的。
FPS 是 Frame per Second 的缩写,意思是每秒产生画面的个数。举例来说,60FPS 指的是每秒产生 60 个画面;90FPS 指的是每秒产生 90 个画面。
90Hz用户体验
当屏幕刷新率和**系统 fps **相对应的时候,才会带来最好的效果。目前的智能手机、显示器以及电视等我们常用的显示设备的屏幕刷新率都是以 60Hz 作为基准,60Hz 就意味着它们每秒能刷新 60 张画面,也就是每秒 60 FPS,虽然大部分影视内容还是采用24帧,不过我们眼睛都会将所见到的信息完整收集,每秒的画面帧数越多,就越连贯,越流畅。屏幕刷新率和内容的帧数其实是相互制约的关系,帧数越高玩游戏就越流畅,但是当内容的帧数超出屏幕刷新率的时候,就需要更高刷新率屏幕的支持了。
从目前的硬件水平来看,90Hz 屏幕 + 90Fps 系统的组合才是目前最好的选择;其他的组合比如 90Hz 屏幕跑 60 fps 的系统,则会有屏幕刷新的时候,系统内容还没有准备好,只能显示上一帧这种情况;比如 60Hz 跑 90 fps 的系统,则会出现丢帧的情况,因为系统内容准备速度要比屏幕刷新速度快,势必有的帧绘制好却没有显示就被丢弃了。
另外 120Hz 的屏幕 + 120 fps 的系统肯定是未来发展的趋势。
什么是Vsync?
VSync 是垂直同期( Vertical Synchronization )的简称。基本的思路是将你的 FPS 和显示器的刷新率同期起来。其目的是避免一种称之为”撕裂”的现象. 对比 60 fps : 60 fps 的系统 , 1s 内需要生成 60 个可供显示的 Frame , 也就是说绘制一帧需要 16.67ms ( 1/60 ) , 才会不掉帧 ( FrameMiss ). 90 fps 的系统 , 1s 内生成 90 个可供显示的 Frame , 也就是说绘制一帧需要 11.11ms ( 1/90 ) , 才不会掉帧 ( FrameMiss ).
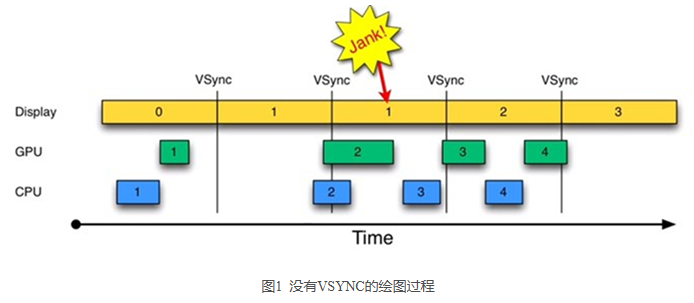
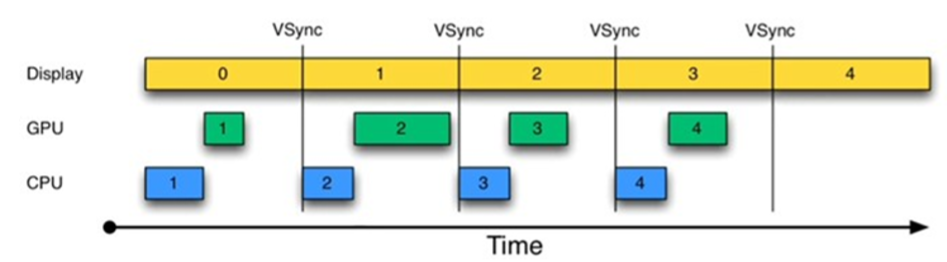
由图1可知:
- 时间从 0 开始,进入第一个 16ms:Display 显示第 0 帧,CPU 处理完第一帧后,GPU 紧接其后处理继续第一帧。三者互不干扰,一切正常。
- 时间进入第二个 16ms:因为早在上一个 16ms 时间内,第 1 帧已经由 CPU,GPU 处理完毕。故 Display 可以直接显示第 1 帧。显示没有问题。但在本 16ms 期间,CPU 和 GPU 却并未及时去绘制第 2 帧数据(注意前面的空白区),而是在本周期快结束时,CPU/GPU 才去处理第 2 帧数据。
- 时间进入第 3 个 16ms,此时 Display 应该显示第 2 帧数据,但由于 CPU 和 GPU 还没有处理完第2帧数据,故 Display 只能继续显示第一帧的数据,结果使得第 1 帧多画了一次(对应时间段上标注了一个 Jank)。
- 通过上述分析可知,此处发生 Jank 的关键问题在于,为何第 1 个 16ms 段内,CPU/GPU 没有及时处理第2帧数据?原因很简单,CPU 可能是在忙别的事情(比如某个应用通过 sleep 固定时间来实现动画的逐帧显示),不知道该到处理 UI 绘制的时间了。可 CPU 一旦想起来要去处理第 2 帧数据,时间又错过了!
为解决这个问题,Project Buffer 引入了 VSYNC,这类似于时钟中断。结果如图 2 所示:
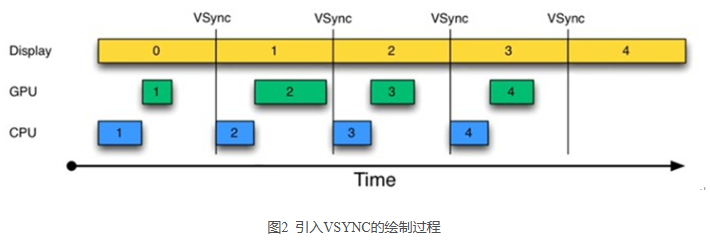
由图 2 可知,每收到 VSYNC 中断,CPU 就开始处理各帧数据。整个过程非常完美。
小结
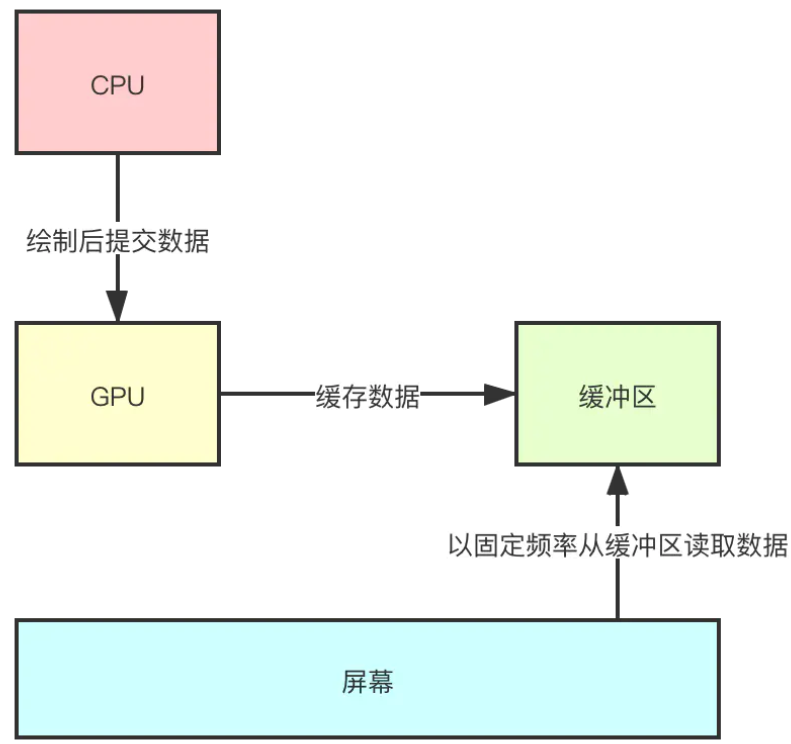
CPU 绘制后提交数据、GPU 进一步处理和缓存数据、最后屏幕从缓冲区中读取数据并显示。平时我们开发过程中主要关心 CPU 绘制部分,对 GPU 和屏幕基本不大关心,这里有必要探索下相关的细节,有助于解决一些实际开发过程中的问题。下文举例没有特殊说明情况下,都是以 16.6 ms 的固定频率进行刷新。
双缓冲机制
根据前面的描述我们知道了屏幕刷新率是固定,以 16.6 ms 的固定屏率从缓冲区取数据进行刷新,但是我们应用层触发绘制的时机是完全随机的(例如我们随时都可以触摸屏幕触发绘制),如果在 GPU 向缓冲区写入数据的同时,屏幕也在向缓冲区读取数据,会发生什么情况呢?有可能屏幕上就会出现一部分是前一帧的画面,一部分是另一帧的画面,这显然是无法接受的,那怎么解决这个问题呢?
这个其实和我们平时开发过程中使用代码管理工具 Git 有一些相似之处,首先我们有一个 master 分支,对应主线代码,当有新的需求来的时候,我们往往不会在 master 分支上直接进行开发,都会拉出一个新的临时分支,例如 developer 分支,在 developer 分支上开发新需求,等开发完成测试通过后才会合到 master 分支。
所以,在屏幕刷新中,Android 系统引入了双缓冲机制。GPU 只向 Back Buffer 中写入绘制数据,且 GPU 会定期交换 Back Buffer 和 Frame Buffer,也就是让 Back Buffer 变成 Frame Buffer 交给屏幕进行绘制,让原先的 Frame Buffer 变成 Back Buffer 进行数据写入。交换的频率也是 60 次/秒,这就与屏幕的刷新频率保持了同步。
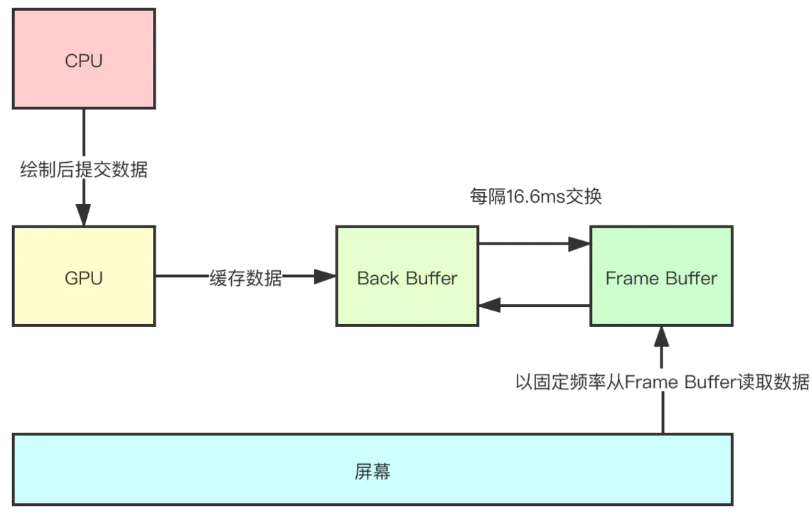
虽然我们引入了双缓冲机制,但是我们知道,当布局比较复杂,或设备性能较差的时候,CPU 并不能保证在 16.6 ms 内就完成绘制数据的计算,所以这里系统由做了一个处理。
当你的应用正在往 Back Buffer 中填充数据时,系统会将 Back Buffer 锁定。如果到了 GPU 交换两个 Buffer 的时间点,你的应用还在往 Back Buffer 中填充数据,GPU 会发现 Back Buffer 被锁定了,它会放弃这次交换
这样做的后果就是手机屏幕仍然显示原先的图像,这就是我们常常说的丢帧,所以为了避免丢帧的发生,我们就要尽量减少布局层级,减少不必要的 View 的 invalidate 调用,减少大量对象的创建(GC 也会占用 CPU 时间)等等。
Choreographer
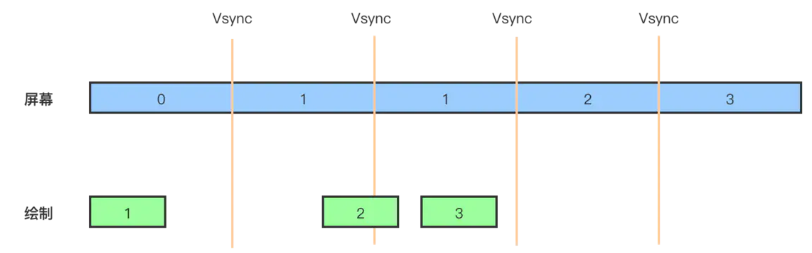
我们看下面这张图,这里已经是基于双缓冲机制,且应用层的优化已经做得非常好,绘制时间均少于 16.6 ms,但依然出现了丢帧,为什么呢?
原因是第 2 帧虽然绘制时间少于 16.6 ms,但是绘制开始的时间距离 vsync 信号(就是一个发起屏幕刷新的信号,Vertical Synchronization 的缩写)发出的时间比较短暂,导致当 vsync 信号来的时候,第 2 帧还没有绘制完成,所以 Back Buffer 依然是锁定的状态,也就出现了丢帧
如果我们可以保证每次绘制开始的时间和 vsync 信号发起的时间一致(如下图所示),是不是就可以解决这个问题呢?
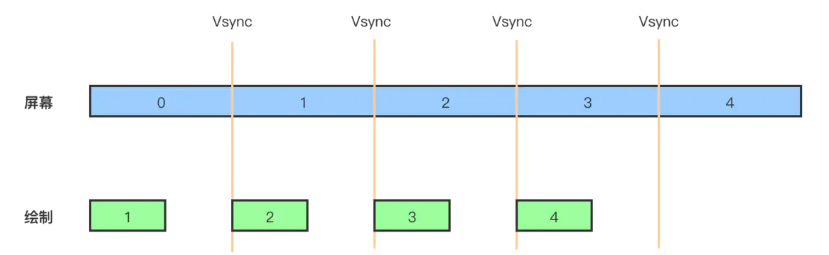
Android 在每一帧中实际上只是完成三个操作,分别是输入(Input)、动画(Animation)、绘制(Draw)。在 Android 4.1(API 16) 之后,Android 系统开始加入 Choreographer 这个类,这个类名翻译过来就是“舞蹈指导”,字面上的意思就是指挥三个 UI 操作一起完成一支舞蹈。这个类就可以解决 vsync 和绘制不同步的问题,其实它的原理用一句话总结就是往 Choreographer 里发一个消息,最快也要等到下一个 vsync 信号来到的时候才会开始处理消息。这样应用总是在 VSYNC 边界上开始绘制,而 SurfaceFlinger 总是 VSYNC 边界上进行合成。这样可以消除卡顿,并提升图形的视觉表现。
三缓冲机制
在 Android 4.1 之前,Android 使用双缓冲机制。怎么理解呢?一般来说,不同的 View 或者 Activity 它们都会共用一个 Window,也就是共用同一个 Surface。 而每个 Surface 都会有一个 BufferQueue 缓存队列,但是这个队列会由 SurfaceFlinger 管理,通过匿名共享内存机制与 App 应用层交互。
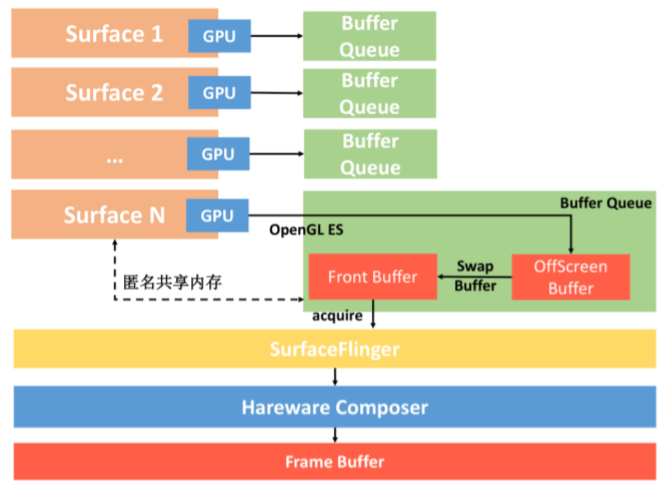
每个 Surface 对应的 BufferQueue 内部都有两个 Graphic Buffer ,一个用于绘制一个 用于显示。我们会把内容先绘制到离屏缓冲区(OffScreen Buffer),在需要显示时, 才把离屏缓冲区的内容通过 Swap Buffer 复制到 Front Graphic Buffer 中。
这样 SurfaceFlinge 就拿到了某个 Surface 最终要显示的内容,但是同一时间我们可能 会有多个 Surface。这里面可能是不同应用的 Surface,也可能是同一个应用里面类似 SurefaceView 和 TextureView,它们都会有自己单独的 Surface。
这个时候 SurfaceFlinger 把所有 Surface 要显示的内容统一交给 Hareware Composer,它会根据位置、Z-Order 顺序等信息合成为最终屏幕需要显示的内容,而 这个内容会交给系统的帧缓冲区 Frame Buffer 来显示(Frame Buffer 是非常底层的, 可以理解为屏幕显示的抽象)。
整个流程如下: 如果你理解了双缓冲机制的原理,那就非常容易理解什么是三缓冲区了。如果只有两个 Graphic Buffer 缓存区 A 和 B,如果 CPU/GPU 绘制过程较长,超过了一个 VSYNC 信号 周期,因为缓冲区 B 中的数据还没有准备完成,所以只能继续展示 A 缓冲区的内容,这样 缓冲区 A 和 B 都分别被显示设备和 GPU 占用,CPU 无法准备下一帧的数据。
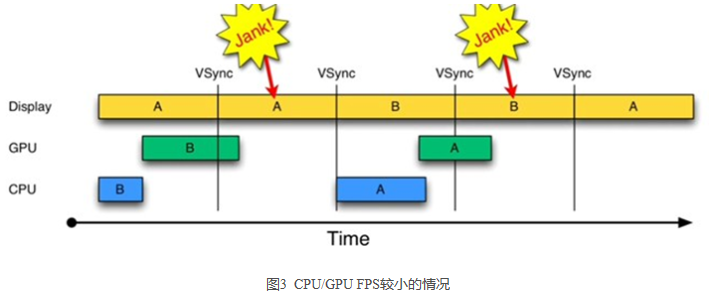
由图 3 可知:
- 在第二个 16ms 时间段,Display 本应显示 B 帧,但却因为 GPU 还在处理 B 帧,导致 A 帧被重复显示。
- 同理,在第二个 16ms 时间段内,CPU 无所事事,因为 A Buffer 被 Display 在使用。B Buffer 被 GPU 在使用。注意,一旦过了 VSYNC 时间点,CPU 就不能被触发以处理绘制工作了。
为什么 CPU 不能在第二个 16ms 处开始绘制工作呢?原因就是只有两个 Buffer。如果有第三个 Buffer 的存在,CPU 就能直接使用它,而不至于空闲。出于这一思路就引出了 Triple Buffer,再提供一个缓冲区,CPU、GPU 和显示设备都能使用各自的缓冲区工作,互不影响。 简单来说,三缓冲机制就是在双缓冲机制基础上增加了一个 Graphic Buffer 缓冲区,这样 可以最大限度的利用空闲时间,带来的坏处是多使用的了一个 Graphic Buffer 所占用的内存。
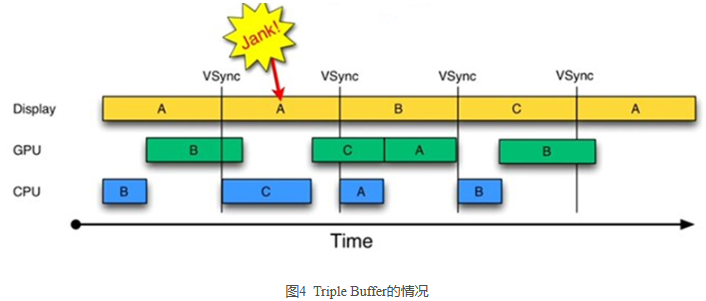
由图 4 可知:
- 第二个 16ms 时间段,CPU 使用 C Buffer 绘图。虽然还是会多显示 A 帧一次,但后续显示就比较顺畅了。是不是 Buffer 越多越好呢?回答是否定的。由图 4 可知,在第二个时间段内,CPU 绘制的第 C 帧数据要到第四个 16ms 才能显示,这比双 Buffer 情况多了 16ms 延迟。所以,Buffer 最好还是两个,三个足矣。
检查 GPU 渲染速度和过度绘制
UI 渲染绘制流水线:
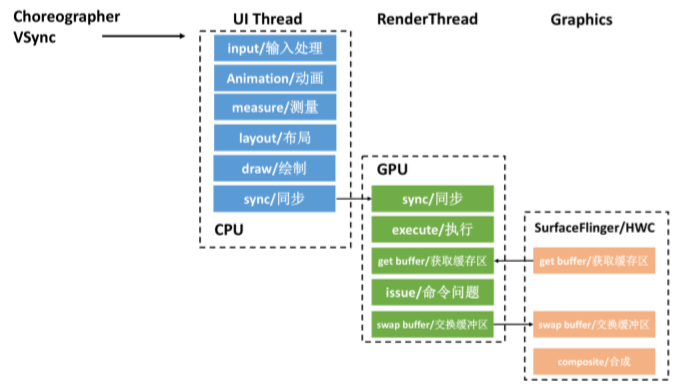
启用分析器
开始前,请确保您使用的是运行 Android 4.1(API 级别 16)或更高版本的设备,并启用开发者选项。要在使用您的应用时开始分析设备 GPU 渲染,请按以下步骤操作:
- 在您的设备上,转到设置并点按开发者选项。
- 在监控部分中,选择 GPU 渲染模式分析。
- 在“GPU 渲染模式分析”对话框中,选择在屏幕上显示为竖条,以在设备的屏幕上叠加图形。
- 打开您要分析的应用。
检查输出
在图 1 中显示的 GPU 渲染模式分析图形的放大图像中,您可以看到 Android 6.0(API 级别 23)上显示的彩色部分。
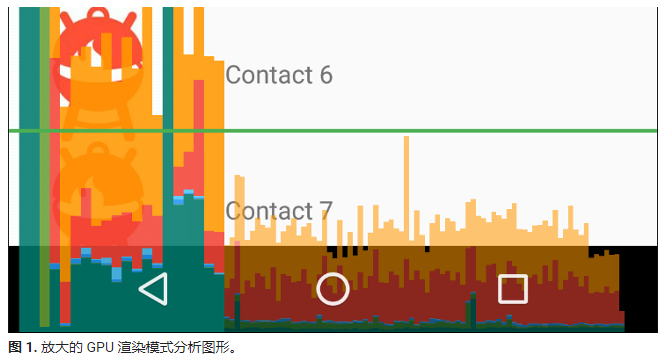
下面是有关输出的几点注意事项:
- 对于每个可见应用,该工具将显示一个图形。
- 沿水平轴的每个竖条代表一个帧,每个竖条的高度表示渲染该帧所花的时间(以毫秒为单位)。
- 水平绿线表示 16 毫秒。要实现每秒 60 帧,代表每个帧的竖条需要保持在此线以下。当竖条超出此线时,可能会使动画出现暂停。
- 该工具通过加宽对应的竖条并降低透明度来突出显示超出 16 毫秒阈值的帧。
- 每个竖条都有与渲染管道中某个阶段对应的彩色区段。区段数因设备的 API 级别不同而异。
下表介绍了使用运行 Android 6.0 及更高版本的设备时分析器输出中某个竖条的每个区段。
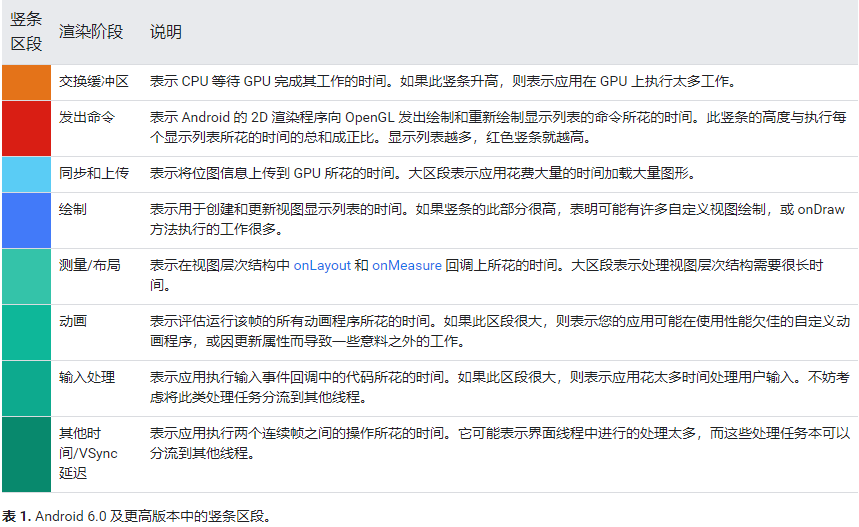
GPU 渲染模式分析图表中显示的每个竖条中的每个分段都表示流水线的一个阶段,并在条形图中使用特定的颜色突出显示。图 2 说明了显示的每种颜色所代表的含义。

了解每种颜色所代表的含义后,就可以针对应用的特定方面来优化其渲染性能。
过度绘制
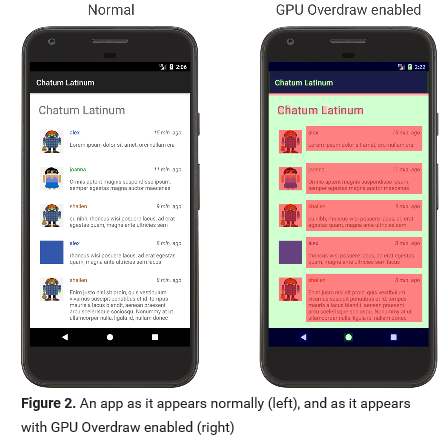
Android 将按如下方式为界面元素着色,以确定过度绘制的次数: